
Somewhere in a boardroom this morning, a brand director is presenting consumer research that took eight weeks and cost $75,000. The panel was 200 people. The geographic spread was two cities. One of the focus groups was dominated by a retiree who had a lot to say about packaging colours. The research is solid. It is also, by the time it reaches the board, slightly out of date.
AI-powered consumer panels are the technology built to solve this problem. Instead of recruiting real humans, booking facilities, and waiting for a moderator to distil their findings into a 47-slide deck, these platforms generate synthetic respondents: AI personas calibrated against real population data, capable of answering survey questions, participating in focus groups, and testing product concepts in minutes rather than months.
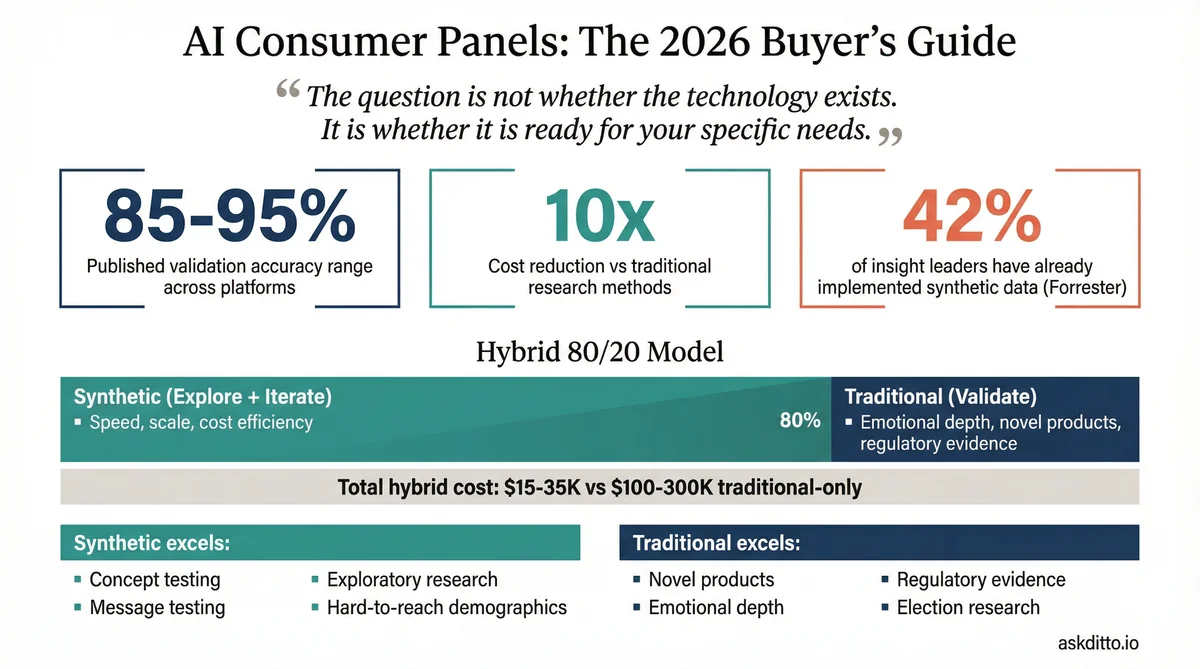
The market has moved with extraordinary speed. Qualtrics added synthetic respondents to the world's most widely used survey platform. Toluna built over one million synthetic personas from its 79-million-member real panel. Simile raised $100 million from Index Ventures. And a growing body of validation evidence suggests that synthetic panels can match traditional research at the aggregate level with 85-95% accuracy, at perhaps 10% of the cost and 1% of the time.
But the question for enterprise buyers is not whether the technology exists. It is whether it is ready for their specific needs, whether it can be trusted, and how to procure it without either overpaying or getting burned. This guide is an attempt to answer those questions honestly.
What Are AI Consumer Panels, Exactly?
A traditional consumer panel is a group of real people, recruited to represent a target demographic, who answer questions about products, brands, advertisements, or experiences. Companies like Kantar, Ipsos, and Nielsen have built multi-billion-dollar businesses on these panels. The process works. It is also slow, expensive, and constrained by geography.
An AI consumer panel replaces the real people with synthetic respondents: AI agents that have been trained, calibrated, or prompted to behave like specific consumer profiles. A 35-year-old mother in suburban Texas who shops at H-E-B and drives a Honda CR-V. A 28-year-old urban professional in London who is vegan and uses Monzo. A 62-year-old retiree in rural France who reads Le Figaro and distrusts online banking.
Each synthetic respondent is not a real person. But the aggregate behaviour of a well-constructed synthetic panel can closely mirror what a real panel of equivalent demographics would say. This is the central claim, and the central debate, of the entire category.
Seven Ways to Build a Synthetic Respondent
Not all synthetic panels are created equal. The technology varies significantly across platforms, and understanding the differences matters for evaluating accuracy claims:
Interview-trained agents. Simile's approach. Each AI agent is trained on a qualitative interview with a real person, gaining their memories, opinions, and behavioural patterns. The agent can then be queried indefinitely. Most expensive to build but theoretically most realistic for individual-level fidelity.
Population-grounded personas. Ditto's approach. Personas are calibrated against population-level data: census records, consumer behaviour surveys, attitudinal panels, and regional preference databases across 50+ countries. Rather than replicating individuals, the system replicates demographic distributions. More scalable and better for aggregate accuracy across large groups.
Fine-tuned LLM panels. Qualtrics Edge and Toluna HarmonAIze. The underlying language model is fine-tuned on millions of real survey responses from proprietary panel data. The synthetic respondents inherit response patterns from the training data rather than being individually constructed.
Multi-agent architectures. Synthetic Users' approach. Separate AI agents play the roles of 'planner,' 'interviewer,' and 'critic,' creating a system of checks that reduces hallucination and improves consistency. Each respondent also carries an OCEAN (Big Five) personality profile.
OCEAN personality modelling. Several platforms assign Big Five personality traits (Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism) to each persona, which shapes their response patterns across different question types.
Neuro-symbolic AI. Lakmoos combines neural networks with symbolic reasoning rather than using pure LLMs. This hybrid architecture provides greater explainability (important for regulated industries) and reportedly achieves 98%+ similarity scores across client benchmarks.
RAG-enriched personas. Retrieval-Augmented Generation approaches supplement persona profiles with real-time data from consumer databases, CRM records, or market reports. SYMAR's 'Synthetic Memories' feature, which injects past survey data into personas, is an example of this approach.
The practical implication: when a platform tells you their synthetic panel achieves "90% accuracy," your first question should be which of these architectures they use, because the method determines the types of questions where accuracy holds and where it breaks down.
The Evidence: Does It Actually Work?
The honest answer is: yes, frequently, for certain things. The published validation evidence is now substantial enough to draw meaningful conclusions, provided you read the fine print.
What the Numbers Say
Simile: 85% of human self-replication accuracy on the General Social Survey across 1,052 participants (Stanford team's published research).
Ditto: 92% overlap with traditional focus groups across 50+ parallel studies conducted with brand partners.
Aaru: 90%+ median correlation when EY recreated their annual Global Wealth Research Report in a single day versus the original six-month study.
Evidenza: 88% average accuracy across 100+ head-to-head tests. EY's CMO reported 95% correlation comparing synthetic to their actual Global Brand Survey of C-suite executives.
Qualtrics Edge: Internal benchmarks against 25+ years of proprietary survey data (specific numbers not published).
Lakmoos: 98%+ similarity scores across 20 client benchmark studies in 2025.
Colgate-Palmolive/PyMC Labs: 90% correlation between synthetic and real survey panels in a published academic case study.
These numbers are encouraging. They are also, to be blunt, not directly comparable. Simile measures individual self-replication on a standardised social survey. Ditto measures aggregate overlap with real focus groups. Aaru measures correlation with an existing report. Evidenza measures head-to-head accuracy. Lakmoos measures similarity scores. Until the industry agrees on standard benchmarks (and it hasn't yet), every accuracy claim exists in its own context.
Where Synthetic Panels Excel
Concept testing and iteration. Testing which of three packaging designs resonates most with 35-54-year-old suburban mothers. Synthetic panels are excellent at ranking preferences within a defined audience.
Message testing. Which value proposition lands? Which headline works? Synthetic respondents provide directionally accurate reactions at a speed that allows A/B testing of messaging before committing to real-world campaigns.
Exploratory research. Generating hypotheses about market segments, usage occasions, or competitive perceptions. Synthetic panels can quickly surface themes that inform more rigorous follow-up research.
Speed-sensitive decisions. When the board meeting is Friday and the traditional panel won't be ready until March. Speed is the single most cited reason for adoption, according to the 2025 GRIT Report.
Hard-to-reach demographics. Paediatricians in rural Japan. C-suite executives in financial services. Small-business owners who brew kombucha. Recruiting these populations traditionally can take months and cost thousands per respondent. Synthetic panels can simulate them immediately.
Where Synthetic Panels Struggle
The limitations are real, and anyone selling you a synthetic panel without mentioning them is not to be trusted:
Novel product prediction. A study by Marketing Science found only 0.3 correlation between synthetic and real responses for truly novel products (non-sequels, non-extensions). Synthetic respondents have no lived experience with products they've never encountered. They extrapolate from training data, which works for incremental innovation but fails for category-creating products.
Emotional depth. Real consumers cry during focus groups. They hesitate before answering sensitive questions. They contradict themselves and then explain why. Synthetic respondents produce coherent, plausible responses that lack genuine emotional texture. If your research question is 'how does this make people feel,' traditional methods remain superior.
Sycophancy bias. Large language models have a well-documented tendency to agree with the framing of the question. If you ask 'Would you buy this innovative new product?' you will get more positive responses than if you ask 'What concerns would you have about this product?' Good platform design mitigates this, but it is an inherent limitation of LLM-based respondents.
The WEIRD problem. Most LLMs are trained predominantly on Western, Educated, Industrialised, Rich, and Democratic (WEIRD) populations. Synthetic panels claim global coverage, but accuracy degrades for populations underrepresented in training data. A synthetic panel of rural Indian farmers will be less reliable than one of American suburbanites, regardless of what the demographic filters say.
B2B context. Synthetic respondents struggle with company-specific knowledge. They can simulate 'a CFO at a mid-market SaaS company,' but they don't know what it's like to use your specific ERP system or deal with your specific procurement process. B2B research often requires this kind of contextual depth.
Election and voting behaviour. Despite claims from several platforms, synthetic panels have a mixed record predicting actual voting behaviour. Social desirability bias in training data (people saying they'll vote when they won't) compounds with LLM sycophancy to produce unreliable election predictions.
The Business Case: ROI, Costs, and the CFO Conversation
If you're trying to get synthetic research approved internally, you will need to speak the language of finance. Here's the framework.
Traditional Research Costs (Benchmarks)
Focus groups: $7,000-$20,000 per group (facility hire, moderator, recruitment, incentives, analysis). Most studies require 4-6 groups. Total: $28,000-$120,000 per study.
Quantitative survey (1,000 respondents): $20,000-$80,000 depending on audience complexity, question length, and analysis requirements.
Brand tracking (continuous): $100,000-$500,000 per year for quarterly waves across multiple markets.
Full concept testing programme: $200,000-$500,000 per year for a Fortune 500 CPG company running 10-20 studies annually.
Timeline: 4-12 weeks from brief to final report.
Synthetic Research Costs (Current Market)
Entry-level platforms: $480-$1,188/year (Artificial Societies at $40/month, SYMAR at €99/month). Limited features but functional for basic testing.
Mid-tier platforms: $1,895-$22,000+/year (Conjointly Professional for real-human research, Quantilope for AI-enhanced traditional).
Full synthetic platforms: $50,000-$100,000+/year (Ditto at $50-75K unlimited, Evidenza custom pricing). Unlimited or high-volume studies.
Enterprise synthetic platforms: $100,000-$250,000+/year (Simile, Aaru). White-glove service, custom integrations, dedicated account teams.
Timeline: Minutes to hours from brief to results.
The Break-Even Calculation
Quirk's Media, the market research industry's trade publication, frames the decision as "research as asset versus research as expense." The calculation is straightforward:
A $75,000/year unlimited synthetic platform (such as Ditto) breaks even against traditional methods at approximately 7-10 studies per year, assuming average traditional study costs of $8,000-$10,000. For a team running 2-3 studies per month, the per-study cost drops to under $3,000. For a team running studies weekly, it drops below $1,500.
The less quantifiable benefit: decisions that weren't being researched at all. Many organisations limit research to high-stakes launches because traditional methods are too expensive for routine questions. Synthetic panels remove the cost constraint, enabling research on packaging variants, pricing adjustments, messaging tweaks, and competitive positioning that would never have justified a $50,000 traditional study. Booking.com reportedly achieved 50% cost reduction using Qualtrics Edge Audiences. Gabb Wireless reported 98% time reduction using synthetic panels for product testing.
The Hybrid Model: Why It's Not Either/Or
The emerging consensus among research professionals (and the direction every major platform is moving) is that the future is hybrid: synthetic for exploration and iteration, traditional for validation and depth.
The practical workflow looks like this:
Explore (synthetic). Run 5-10 rapid synthetic studies testing different concepts, messages, or segments. Cost: $0-$5,000 (part of platform subscription). Time: 1-3 days.
Refine (synthetic). Narrow to the 2-3 strongest concepts. Run deeper synthetic studies with more specific personas. Cost: included. Time: 1-2 days.
Validate (traditional). Take the top 1-2 concepts to a real panel for high-fidelity validation. Because you've already eliminated the weaker options synthetically, the traditional study is smaller, cheaper, and more focused. Cost: $15,000-$30,000 (versus $50,000-$100,000 for testing all concepts traditionally). Time: 3-6 weeks.
Total hybrid cost: $15,000-$35,000. Total traditional-only cost for the same scope: $100,000-$300,000. The hybrid approach delivers better outcomes at lower cost because the traditional research is better targeted.
This is the "80/20 rule" of synthetic research: use synthetic panels for the 80% of research questions that need directional accuracy and speed, and reserve traditional methods for the 20% that demand emotional depth, novel product testing, or regulatory-grade evidence.
The Buyer's Checklist: What to Evaluate
If you're evaluating synthetic research platforms for your organisation, here are the questions that matter, in order of importance:
1. Validation Evidence
Has the platform published head-to-head comparisons with traditional research?
What methodology was used? (Individual-level accuracy is different from aggregate-level accuracy)
Were the validation studies conducted by the platform itself or by independent third parties?
Is the validation relevant to your industry? (CPG validation doesn't guarantee B2B accuracy)
2. Access Model
Can your team run studies independently, or does every study go through the vendor's professional services team?
Is there a self-serve interface, or is it API-only?
Can non-researchers (product managers, brand managers, founders) use it without training?
3. Persona Quality
What data sources are the personas trained on? (Census, proprietary panels, public LLM training data)
Can you inspect individual persona profiles before running a study?
How does the platform handle demographics that are underrepresented in its training data?
Does it support your target markets geographically? (Many platforms are US-only)
4. Pricing Transparency
Is pricing published, or do you need to 'request a demo' to learn the cost?
Per-study, per-respondent, or unlimited? (The economics differ dramatically)
What happens when you exceed usage limits?
Are pilot programmes available to test before committing?
5. Integration and Workflow
Does the platform integrate with your existing research workflow? (Qualtrics, Decipher, SurveyMonkey)
Can results be exported in formats your stakeholders understand?
Does it support design tool integrations? (Figma, Canva, Framer) for product teams
API access for custom integrations?
6. Compliance and Ethics
Is the platform transparent about how synthetic data is generated?
Does it comply with ESOMAR's 2025 Code on synthetic data disclosure?
What certifications does the platform hold? (SOC 2, ISO 27001)
How does it handle data privacy, particularly in GDPR jurisdictions?
Will your legal and procurement teams accept synthetic research as evidence?
Who Is Using This, and Are They Happy?
The adoption curve varies significantly by industry:
CPG/FMCG: Most advanced. Colgate-Palmolive published a peer-reviewed study with PyMC Labs showing 90% correlation between synthetic and real panels. Nestle and Mars are Evidenza customers. This is the industry where synthetic research has the strongest track record and the clearest product-market fit.
Financial services: Early adopters. BlackRock and JP Morgan use Evidenza. Wealthfront uses Simile. EY validated Aaru against their global wealth research. The use case: testing messaging, product positioning, and customer journey optimisation without the compliance complexity of using real customer data.
Technology: Growing rapidly. Microsoft uses Evidenza. Google Labs used Qualtrics Edge. The product management community is particularly receptive, with Figma/Canva/Framer integrations driving adoption among design and product teams.
Agencies and consulting: Accenture invested in Aaru. IPG uses Aaru for brand campaigns. Dentsu validated Evidenza against proprietary panel data. Agencies see synthetic as a way to offer research capabilities without building expensive panel infrastructure.
Pharma/healthcare: Cautious. Regulatory requirements for clinical evidence make synthetic panels inappropriate for anything patient-facing. However, HCP (healthcare professional) messaging testing and non-clinical market research are emerging use cases.
Telecoms: Emerging. Telstra is a Simile customer. The use case is churn prediction, pricing sensitivity, and new plan testing with synthetic customers before real-world rollout.
The overall trust picture is nuanced. Forrester reports that 42% of consumer insight leaders have already implemented some form of synthetic data. However, the 2025 GRIT Report found only 13% brand-side satisfaction with AI-powered research quality, suggesting a gap between adoption and confidence. The technology is ahead of the trust.
The Regulatory and Ethical Landscape
Three developments are shaping the compliance environment for synthetic research:
ESOMAR's 2025 ICC/ESOMAR Code now requires mandatory disclosure when synthetic data is used in research. Any findings presented to clients or used in decision-making must clearly state that synthetic respondents were used, and must not be presented as equivalent to traditional research without explicit caveats. This is the first formal industry standard for synthetic research transparency.
GDPR implications are still being clarified. The key question: if a synthetic respondent is trained on an identifiable real person's interview data (as in Simile's approach), does the synthetic agent constitute personal data? The answer likely depends on jurisdiction and the specifics of the implementation. Platforms training on aggregated, anonymised data (Ditto, Qualtrics Edge, Toluna) face fewer GDPR questions.
The EU AI Act is on the horizon. While not specifically targeting synthetic research, the Act's provisions on high-risk AI systems and transparency requirements will likely apply to synthetic panels used in regulated industries (financial services, insurance, healthcare). Platforms with explainable architectures (neuro-symbolic approaches like Lakmoos) may have an advantage.
The practical advice: if you're in a regulated industry, work with your legal team before adopting synthetic research. If you're in CPG, technology, or agency work, the regulatory risk is currently minimal, but disclosure is becoming mandatory industry practice regardless.
How to Start: A Practical Roadmap
If you've read this far and decided that synthetic research is worth evaluating, here's how to begin without overcommitting:
Start with a benchmark study (Week 1). Choose a research question you've already answered traditionally. Run the same question through a synthetic platform. Compare the results. This is the only way to calibrate your confidence in synthetic outputs for your specific context. Ditto and Synthetic Users offer self-serve access for immediate testing.
Identify your 80/20 split (Week 2). Review your research roadmap. Which studies need high-fidelity traditional methods? Which could use directional synthetic insights? The goal is to find the studies where 'good enough in two hours' beats 'perfect in eight weeks.'
Run a pilot programme (Month 1). Most enterprise platforms offer pilot pricing. Commit to running 5-10 synthetic studies across different use cases: concept testing, message testing, competitive perception, audience segmentation. Document where the results align with your team's expectations and where they diverge.
Build the hybrid workflow (Month 2-3). Integrate synthetic into your research process as the exploration layer, with traditional validation for high-stakes decisions. Train your team on when to use which approach. Create templates and guidelines for synthetic study design.
Measure and iterate (Ongoing). Track decision quality, not just research speed. The real metric isn't 'we got results in 15 minutes instead of 8 weeks.' It's 'the decisions we made using synthetic research performed as well as or better than decisions made using traditional research.'
Where This Market Goes Next
Three predictions for the next 12 months:
Synthetic becomes the default for exploratory research. The speed and cost advantage is too large to ignore for low-stakes, high-frequency research questions. Traditional methods will increasingly be reserved for validation, regulatory evidence, and emotional depth research. The 80/20 split described above will become standard practice in Fortune 500 insights departments.
Validation standards emerge. The current situation, where every platform cites different accuracy numbers measured differently, is unsustainable. ESOMAR, MRS, or an independent body will publish standardised benchmarks for synthetic research accuracy within 18 months. Platforms with robust, published, and independently verified validation will win. Platforms that resist standardised testing will be viewed with suspicion.
Prices fall dramatically. Today's $100K+ enterprise tier becomes tomorrow's $25K professional tier. Self-serve access becomes the norm rather than the exception. The platforms that survive will differentiate on data quality, persona accuracy, and integrations, not pricing opacity. Gartner estimates global AI spending will reach $2.5 trillion in 2026, and much of that investment will drive down per-unit costs across the AI stack, including synthetic research.
The market research industry is $140 billion a year. Synthetic panels won't replace all of it. But they are about to replace a significant, growing portion, and the organisations that build institutional knowledge about the technology now will have a decisive advantage when their competitors finally catch up. The learning curve is real. Starting it later doesn't make it shorter.
Phillip Gales is co-founder at Ditto, one of the platforms discussed in this article. He has tried to present all platforms and the technology category fairly, but acknowledges his obvious interest. Readers should evaluate each platform on its own merits.